
1、模型背景
1957年,Jaynes提出了最大熵(Maximum Entropy, MAXENT)理论,最大熵原理在信息科学、物理学、生物学等学科应用广泛。近几十年,最大熵原理逐渐被应用于生态学领域,主要包括两个方面:一是根据最大熵原理建立物种分布模型,研究物种出现的概率、生境适宜度或物种丰富度等情况;二是被应用到生物多样性、群落生态学的相关研究中。基于最大熵原理,Phillips等2006年人开发了用于物种分布模拟的Maxent软件。该软件可以直接产生生境适宜度空间分布地图,可以得到各个环境变量对于生境适宜度的响应曲线,同时可由模型内嵌的Jackknife检验直接得到各个环境变量对于目标物种生境适宜度的重要性。随着人们对于野生动植物生境关注度的提高,以及基于最大熵原理的生境适宜度模型本身的优势,越来越多物种的基于最大熵原理的生境适宜度模型被建立起来。
Maxent模型由Steven Phillips,Miro Dudik和Rob Schapire编写的物种地理分布最大熵建模程序,得到普林斯顿大学AT&T实验室研究和美国自然历史博物馆生物多样性与保护中心的支持。
该页面包含MaxEnt程序的参考信息。 关于该方法的背景信息可以在以下两篇论文中找到:
Steven J. Phillips, Robert P. Anderson, Robert E. Schapire.Maximum entropy modeling of species geographic distributions.Ecological Modelling, Vol 190/3-4 pp 231-259, 2006.
Steven J. Phillips, Miroslav Dudik.Modeling of species distributions with Maxent: new extensions and a comprehensive evaluation. Ecography, Vol 31 pp 161-175, 2008.
2、模型运行及结果输出
2.1 关于模型输入
教程假设所有的数据文件与maxent程序文件在相同的路径下,否则将需要在这里使用的文件名前加上这个路径(c:\data\maxent\tutorial)。
运行程序,需要提供一个包含了存在位置信息的文件(“samples”),一个包含了环境变量的文件,以及一个输出文件。除了经纬度坐标系统,其他坐标系统也可用于样本文件,环境变量文件必须与样本文件使用相同的坐标系统。在样本文件里,“x”坐标(在我们的例子里是经度)应排在“y”坐标(纬度)之前。如果存在数据有重复的记录(在一个相同的网格单元里有同一物种的多个记录),系统默认移除重复的记录。在“Settings”里,取消选择“Remove duplicate presence records”可以不移除重复的记录。
“layers”文件包含了许多ascii光栅网格(in ESRI’s .asc format),每个都描述了一个环境变量。网格必须都有相同的地理范围和大小(所有的ascii文件的标题必须互相匹配的很好)。我们例子中的一个变量,“ecoreg”,是一个分类变量,描述潜在的植被分类。类别必须用数字表述,不能用字母或单词。在程序中,如图所示,必须勾选出变量的类型,是连续变量还是分类变量。
增益(gain)与偏差密切相关,它在广义加性模型和广义线性模型中是拟合优度/适合度/吻合度的一个度量。在模型运行过程中,增益从0开始,逐渐增加,逼近一个渐近线。在这个过程中,Maxent在单元格的每个像素上都产生了一个概率分布,模型从均匀分布开始,反复提高对数据的拟合度。增益的定义是存在样本的平均对数概率值减去一个常数,这个常数使得均匀分布的增益为0。在运行结束时,增益表明模型对存在样本的聚集有多紧密。例如,如果增益是2,存在样本的平均可能性是一个随机背景像素可能性值的exp(2) ≈ 7.4倍。值得注意的是,Maxent不是直接计算“出现概率”。它分配给每个像素的可能性通常非常小,因为一个单元格里的所有像素的概率值之和必须为1(though we return to this point when we compare output formats)。
测试的点是从物种存在数据中随机选出来的。每次在基于同一个数据集运行Maxent的时候,随机样本都是相同的,除非在设置中选择“random seed”这一选项。还有一种选择是,一个或更多物种的测试数据可以放在一个单独的文件里,通过设置里的“Test sample file”输入到程序中。
2.2 关于模型输出
Maxent 的模型值的输出有三种格式:原始输出、累计输出和逻辑输出。首先,原始输出就是Maxent 指数模型本身。其次,与一个原始值r对应的累计值就是原始值不超过r的最大熵分布的百分比。预测的假阴性率可以很好地解释累计输出:如果把累计的临界值设为c,Maxent分布本身的抽样过程中得到的两分类预测结果的假阴性率可能为c %,我们可以对物种分布中抽样产生的一个类似的假阴性率进行预测。第三,如果c是maxent分布的熵的指数,那么与一个原始值r对应的logistic value就是c·r/(1+c·r)。这是一个逻辑函数,因为原始值是环境变量的一个指数函数。三个输出格式都是单调的关系,但是它们的比例不同,有不同的解释。默认的输出是logistic(逻辑输出),它是最容易概念化的:它给出了一个存在的可能性的估计值,这个值在0到1之间。
需要注意的是,物种存在可能性依赖于抽样设计的细节,例如the plot size 和自由活动的生物的观测时间;逻辑输出在如下的假设下评价物种存在的可能性:抽样设计中典型的有物种存在的地方的物种存在的可能性约为0.5. 0.5这个值很武断,如果在典型的物种存在地的物种存在可能性的信息是有效的,那么这个值可以被调整(用“default prevalence”参数)。上面Bradypus模型的输出图片使用的是logistic 格式。与之相比,下面的图片给出了原始的输出格式:
值得注意的是,这里使用的是颜色刻度是对数尺度。线性范围主要是蓝色的,因为原始格式通常赋予少数站点相对较大的值,所以其中有一些红色的小斑块(可以在Settings界面取消选定“Logscale pictures”验证)— 这被认为是指数分布给出的原始输出的一种人工因素。
累计输出格式给出了下面的图:就原始输出来说,为了强调较小的值之间的差异,使用了对数尺度来coloring the picture。累计输出可以被解释为预测适合物种的高于某一临界值的条件,大致范围为1-20(或者这幅图中的黄色到橘色),它依赖于应用中可以接受的预测的假阴性水平。
2.3 关于模型校验
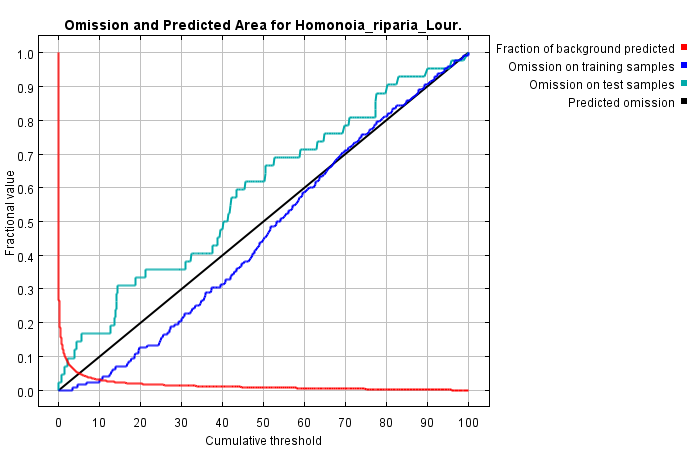
“random test percentage”对应的输入栏里输入25,使得程序随机选择25%的样本记录来进行测试。这使得程序可以进行一些简单的统计分析。大多数分析会使用一个临界值进行一个二元预测,在临界值上条件适宜,在临界值下,条件不适宜。第一个图说明了训练假阴性和测试假阴性以及预测的区域随着累计阈值变化的变化情况,如下图所示:
这里我们可以看出测试样本的假阴性与预测的假阴性率匹配的很好,测试数据的假阴性率来自Maxent分布本身。预测的假阴性率是一条直线,根据累计输出格式定义。在一些情况下,测试的假阴性率的曲线远低于预测的假阴性线:一个常见的原因是测试和训练数据不是相互独立的,例如如果他们来自同一空间自相关的存在数据集。
空间自相关(spatial autocorrelation)是指一些变量在同一个分布区内的观测数据之间潜在的相互依赖性。Tobler(1970)曾指出“地理学第一定律:任何东西与别的东西之间都是相关的,但近处的东西比远处的东西相关性更强”。
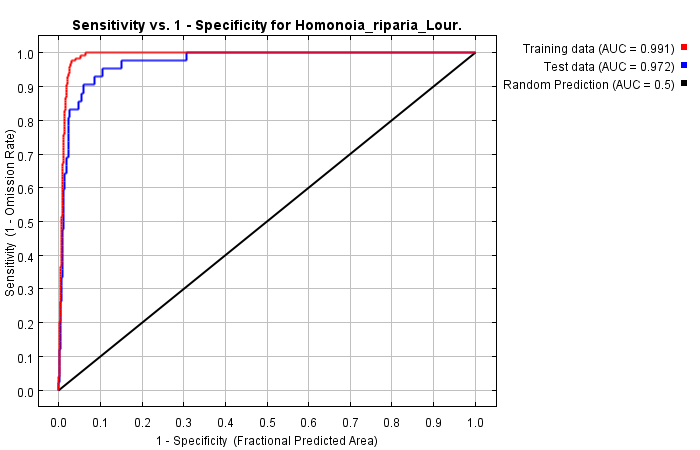
下幅图给出了训练数据和测试数据的接受者操作特征曲线(ROC曲线)。这里也给出了接受者操作特征曲线(ROC曲线)下面积(AUC)。如果有测试数据,测试数据AUC的标准差在随后的网页报告中给出。
如果训练数据集和测试数据集使用相同的数据,那么红色曲线和蓝色曲线就会重叠。如果把数据分成两部分,一部分用来训练,一部分用来测试。红色线(训练的ROC曲线)的AUC比蓝色的(测试的)高。红色线(训练)表明模型对训练数据的拟合度。蓝色线(测试)表明了模型对测试数据的拟合度,是对模型预测能力的真实测试。如果模型表现不如随机模型,蓝绿色线(随机模型的线)就是你所期望的线。如果蓝色线(测试)在蓝绿色线下面,表明模型表现比随机模型还要差。蓝色线的左上角越高,模型对测试样本中的存在情况预测的越好。更多关于AUC统计的信息,可参考:Fielding, A.H. & Bell, J.F. (1997) A review of methods for the assessment of prediction errors in conservation presence/ absence models. Environmental Conservation 24(1): 38-49. 由于只有存在数据,没有缺失数据,用“fractional predicted area”(预测区域的占比)(研究区域中预测有物种出现的面积占总研究面积的百分数)代替更加标准的commission rate(fraction of absences predicted present)。对于这一问题的讨论,see the paper in Ecological Modelling mentioned on Page 1 of this tutorial. 值得注意的是,对于用环境数据描述研究区的研究来说,分布范围窄的物种的AUC值较高。这并不意味着模型更好,相反,这种情况是AUC统计的一种伪迹。
2.4 因子贡献率问题
物种分布模拟的应用可以回答这个问题,模拟的变量中哪些对物种来说更重要?不只一种途径可以回答这个问题,在这里我们列出了Maxent里可以用来处理这个问题的可能的方法。 在Maxent模型训练的过程中,也追踪了哪些环境变量促进了模型的拟合。通过调整单个特性的系数,Maxent算法的每一步都增加了模型的gain值;程序将增加的gain值分配给特性所依赖的环境变量。在训练过程结束时,转化成百分比,就可得到下表中的中间那一列:
| Variable | Percent contribution | Permutation importance |
|---|---|---|
| bio18 | 52.6 | 6.5 |
| bio15 | 18.2 | 24.9 |
| bio3 | 7.4 | 11.9 |
| bio14 | 6.8 | 8.1 |
| bio12 | 5.3 | 0.4 |
| bio7 | 4.6 | 0.2 |
| bio1 | 1.6 | 37.5 |
| bio2 | 1.5 | 0.8 |
| slope | 1.4 | 0.6 |
| bio5 | 0.3 | 0.9 |
| aspect | 0.2 | 0.3 |
| altitude | 0.1 | 8 |
这些贡献的百分比值仅仅是探索式地定义:他们依赖于特定的途径,Maxent使用这一途径得到最优解决方案。不同的算法可能会通过不同的途径得到相同的解决方案,并最终得到不同的percent contribution values(贡献的百分比值)。另外,当有高度相关的环境变量时,解释the percent contributions时要特别谨慎。在我们的例子—Bradypus中,年降水量与10月和7月的降水量高度相关。虽然上面的表显示Maxent得到的结果表明10月降水量的percent contributions最高,年降水量的percent contributions很低,这并不一定意味着对于物种来说,10月降水量远比年降水量重要。表中右边那一列是对variable contributions的一个二次度量,叫做permutation importance。permutation importance仅依赖于最终的Maxent模型,不依赖于得到最终模型的途径。通过随机排列训练数据(存在数据和背景数据)中的变量值,测量训练AUC的减少情况,来确定每个变量的贡献。AUC大幅度的减小表明,模型很大程度上依赖这个变量。归一化这些值给出对应的百分数。 为了得到变量重要性的替代评价,可以勾选“Do jackknife to measure variable important”,运行Jackknife检验。选中该项后,会生成一系列的模型,环境变量被轮流逐一剔除,并用剩余的变量参与运算。同时还会生成一个只包含某一个变量的模型,也会生成一个所有变量都参与运行的模型。Jackknife检验的结果在“bradypus.html”文件中,有三个柱状图,第一个如下图:
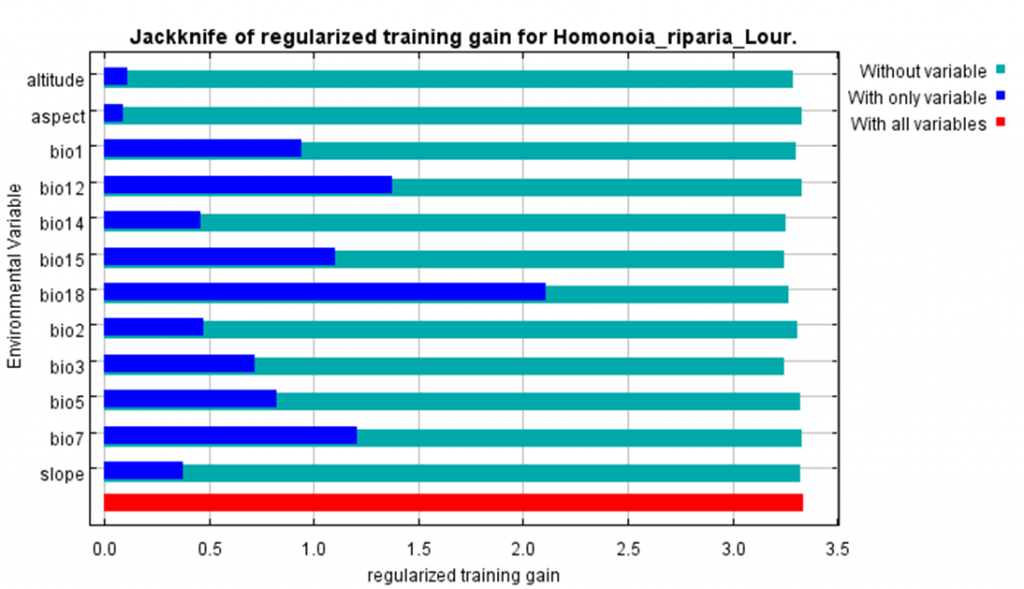
上图中,深蓝色条越长,说明该变量的gain越大,即代表该变量越重要,浅蓝条的长度代表的是除该变量外的其它变量组合的所有贡献和。如上图中的pre6190_11 (average January rainfall),对应的深蓝条很短,说明它本身的gain值几乎接近于0,表明它对预测Bradypus分布来说并不是多重要的信息。另一方面,October rainfall (pre6190_l10) 是对训练数据的一个很好的拟合。图中浅蓝条长度都相差不大,说明没有哪个变量包含大量的十分重要的,其它变量不包含的信息,也就是说,剔除任一个变量,都不会显著减小训练的gain值,即不会对环境产生过大的影响。
bradypus.html 文件还提供了测试数据和AUC值的jackknife test,以检验在test数据中各变量的影响度,以及各变量对AUC值的影响度。需要注意的是,各变量的影响度在training, test和AUC值的三个图中,影响度不一定一致。测试数据和AUC值的jackknife test图如下所示。比较三个jackknife test的结果图很有意义。当使用AUC衡量模型表现时,AUC图显示annual precipitation (pre6190_ann) 是预测被用于测试的出现数据分布的最有效的单变量,即使用所有变量建立的模型中它也很少被用到。与training gain plot 相比,annual precipitation的相对重要性在test gain plot中有所增加。此外,在test gain and AUC plots中,一些浅蓝色的柱子(特别是monthly precipitation variables)比红色的柱子长,这表明不使用对应的变量可以提高模型的预测效果。
monthly precipitation variables 使得Maxent对训练数据有好的拟合,但是annual precipitation variable的概括力更好,对于训练数据可以给出一个更好的结果。换句话说就是,包含monthly precipitation variables的模型似乎可转换性更差。如果要转换模型,例如为了在气候变化条件下评价此物种未来的分布,将模型应用到未来的气候变量中,这点就很重要。monthly precipitation values的转换性更差:Bradypus的可能的适宜条件将不会依赖于选定的几个月的准确降雨量,但是会依赖于总平均降雨量,也可能依赖于降雨的稳定性或lack of extended dry periods. 在大陆范围建模时,季节性降雨的准确时机可能会有转变,并影响monthly precipitation,但却不是Bradypus的适合条件。
总的来说,使用可能与模拟的物种直接相关的变量更好。例如,the Worldclim website (www.worldclim.org) provides “BIOCLIM” variables, 包括派生变量,如“rainfall in the wettest quarter”, rather than monthly values.